
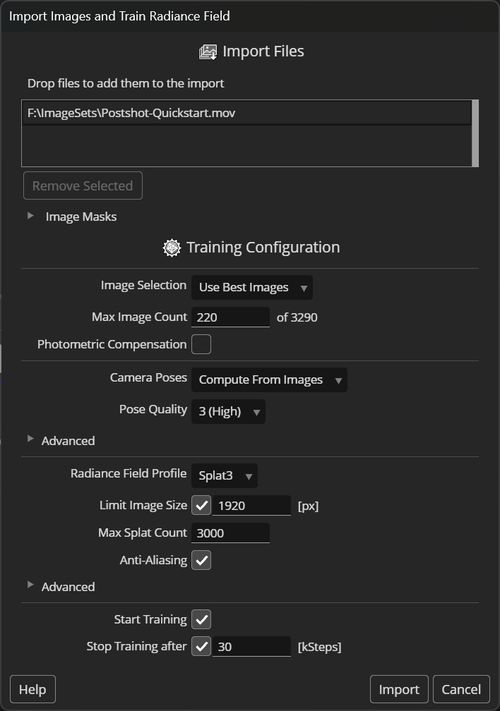
The import popup window shows the list of files that you are about to import. You can add more image-, video-, camera- or point cloud files by dragging and dropping them into the popup window. If you are importing mask files, drop them on the list box below Image Masks instead.
This allows you to train on multiple video files or multiple folders of images shot of the same scene. You can also add camera poses and point clouds extracted from the same images using external tools. See Importing Images for more details.
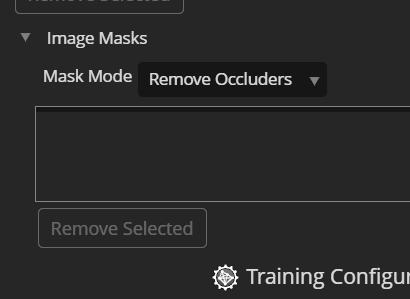 Image Masks are separate black&white images that select some regions in the main input images to be treated differently during training. Many 3rd party tools can create image masks based on different criteria.
Image Masks are separate black&white images that select some regions in the main input images to be treated differently during training. Many 3rd party tools can create image masks based on different criteria.
Mask images must have the same resolution as the associated color images.
To add mask images to the import, drop them on the list box in the Image Masks section.
In order to be associated with the correct color image, the mask image must have the same base filename. The table below shows several mask image filenames that will be associated with the input image.
| Input Image | Valid Mask Filenames |
| images/image001.jpg | masks/image001.jpg |
The Mask Mode specifies how the masks are applied to the input images.
Remove Occluders: the active (white) regions of the mask images will be ignored from the associated input image only. That is, the trained model may still reconstruct pixels in the masked space, but learn it only from other images.
This mode allows removal of unwanted objects in the images.
Remove Background: the inactive (black) regions of the mask images are considered background and must not be reconstructed. That is, the model will be trained to reconstruct empty space (fully transparent pixels) for these regions.
This mode can be used to isolate objects from their background.
Use Best Images: Postshot will select sharp images that are well distributed across the scene for camera tracking and radiance field training. This is a good default to use if you don't want to pre-select images from your capture shot.
Use All Images: All imported images will be used for tracking and training. This setting may cause inferior results to Use Best Images for example if there are blurry images in the import. Using this setting is recommended only if the image sequence has been pre-selected outside of Postshot.
When using the Use Best Images setting above, the Max Image Count value specifies how many images will be selected from the imported image sequence. Typical values range between 100 and 300.
Image counts below 100 are still possible, but most reasonable results require about 100 or more images.
On the other hand, using many more images won't hurt the quality (assuming all images are sharp and well trackable), but they may not improve it either. Using images that were taken from very similar view points won't give the radiance field enough additional information about the scene to justify the processing time.
Selecting this option will compensate for lens vignetting as well as variations in exposure and white balance across the images. This prevents reconstruction artefacts if the exposure varies significantly across the image set.
Check this option if
When importing images or video, Postshot will compute the camera poses from the images - a process also called Camera Tracking. This is a multi-step process and will take some time before the radiance field training can begin.
If you have already tracked your shot with tools, you can also import the camera poses. To do this, simply drop both the images and the camera pose database into Postshot.
Select the desired quality level for camera pose extraction here. Higher quality levels require more processing time, but generate more accurate camera poses. This can result in a sharper reconstruction of fine detail and fewer artefacts.
Single Lens & Focal Length
If you know that all of the imported images or videos were shot with the same lens and focal length setting, checking this option may create more stable camera poses, which ultimately also improves the accuracy of the trained radiance fields.
Postshot supports different profiles to create radiance fields. These profiles differ mostly in the reconstruction quality.
This profile can best reconstruct fine details in both the foreground and background. Compared to the other profiles, it can also better utilize the details of higher resolution images (see also Downsample Images).
The Splat3 profile is currently the recommended profile for most scenes.
Splat MCMC uses a more randomized sampling of the scene than the other models. As a result it may not produce as many fine details. But can also be more forgiving with regard to artefacts in the input images.
This is a legacy profile that differs in the way it densifies the scene during training. Unlike the Splat3 and Splat MCMC profiles, the Splat ADC profile does not allow specifying the maximum number of Splats created. Instead, the Splat Density parameter controls the growth rate of the model size.
To speed up training, the resolution of the input images can be reduced. If enabled, this value specifies the maximum size of the larger dimension of an image. For example, if set to 1920, images of size 3840x2160 will be downscaled to 1920x1080.
Depending on the Model Profile and the Max Splat Count settings, this may lead to a loss in detail in the trained model.
Scenes with lots of fine detail can be reconstructed best using a high Max Splat Count. This will then also require good image resolution, sharpness and camera pose accuracy, which all contribute to the model's ability to reconstruct fine details.
On the other hand, if the scene does not have lots of fine detail or the image sharpness or pose accuracy is not as high, lower image resolutions will suffice and allow faster training.
This parameter is only available when the Splat3 or Splat MCMC profile is selected.
The pararmeter sets a limit on the total number of Gaussian Splatting primitives that the training process will generate. This directly affects how much memory and disk space the radiance field model requires, how fast it can be rendered as well as how much fine detail can be represented.
If the training process reaches the limit and there is still not enough detail resolved in the model, you can increase this value during training or continue training with a different value after training has been paused.
When using the Splat ADC profile, this value controls how much detail will be created in the scene. Values larger than 1.0 cause it to be more sensitive, adding splats already for smaller inaccuracies. Values less than 1.0 make it less sensitive, causing fewer splats to be created.
If there is not enough detail in your splat model, you can try increasing this value. You can change this value during training or continue training with a different value after it has been paused.
Note that the impact of this parameter depends on the image set. The same value may produce different splat counts with other image sets.
Checking this option improves the model quality and prevents artefacts when zooming away from the original camera positions.
Note that this feature may not be supported in some 3rd party viewers. In such viewers the render quality may deteriorate if the model has been trained with this option.
Spherical Harmonics are used to represent direction dependent color effects can help improve the reconstruction quality significantly. But its effectiveness also depends on the materials and lighting in the scene.
Since the sky in outdoor shots usually does not have much texture that guides the reconstruction process, it can result in large floating artefacts that tend to 'hang' much lower than the sky should. Postshot can create a special sky model that may help to reduce such artefacts by projecting the environment onto a large sphere around the scene.
Leave this box checked to automatically start tracking and training after importing the images.
If checked, Postshot will stop training after the specified number of steps. In each step one input image will be processed. By default a step count will be estimated based on the number of images.
While most of the convergence occurs during early training steps, there can still be significant improvements in image quality after twice that amount or more.
support@jawset.com · sales@jawset.com
Imprint · Terms and Conditions · Privacy Policy
© 2026 Jawset Visual Computing